
Para completar los resultados de los tests anteriores hemos hecho nuevos tests y probado también a usar varias máquinas de MongoDB en Sharding. El sharding es algo muy similar al particionamiento horizontal para bases de datos tradicionales.
En este caso nos encontramos con problemas a la hora de usar Apache JMeter (teníamos como respuesta demasiados errores). Desconozco si se debió a un problema de red o de la propia herramienta, pero bueno, decidimos usar le herramienta HP LoadRunner (a mi pesar), que es la que usamos internamente para hacer tests de carga.
Lo más interesante a la hora de utilizar Sharding es configurar la repartición de los datos previamente con Tag Aware Sharding, en vez de dejar que sea MongoDB el que automáticamente distribuya los datos entre los nodos. De esta forma conseguiremos ganar también rendimiento en las operaciones de inserción.
Resultados de los tests
Un resumen de los tests mas significativos sería el siguiente
Tests simples de lectura
| MySQL | MongoDB | |
| Leer todos los objetos con id entre 100 y 110 millones | 10m 5s | 0,15s |
| Seleccionar un registro por id (entre 113 millones) | 0,30s | 0,12s |
| Seleccionar los ids de los registros entre dos fechas | 4m 10s | 0,16s |
| Seleccionar los ids de los registros entre dos fechas y contarlos | 2m 48s | 0,85s |
Tests simples de escritura (inserción de registros)
Aquí ejecutamos scripts sencillos que escriben un registro detrás de otro
| MySQL | MongoDB | |
| 70.000 usuarios | 12s | 3s |
| 1.300.000 dominios | 4m 36s | 58s |
| 1.300.000 dominios con índices | 14m 13s | 8m 27s |
| 5.000.000 de entradas en el log | 2h 10m 54s | 1h 03m 53s |
| 10.000.000 de entradas en el log | 3h 27m 10s | 1h 59m 11s |
| 30.000.000 de entradas en el log | 10h 18m 46s | 5h 55m 25s |
Tests simples de escritura (sin y con Sharding)
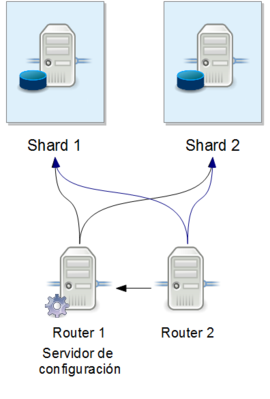
La idea es repartir las entradas repartiéndolas por ID (entre 2 y 4 máquinas). En nuestro caso se indicó a los repartidores (o “routers”) de mongo los rangos de ID’s que correspondían a cada nodo.
Si no lo hubiéramos hecho así la inserción no hubiera ido mejor que con un sólo nodo de MongoDB, ya que el reparto lo hace a posteriori, e inicialmente todos o la mayor parte de las inserciones hubieran sido almacendas en el primero de los nodos.
Para estos tests en vez de entradas de logs como en los anteriores hemos inventado documentos mucho más sencillos (id, pais y dato)
| MySQL | MongoDB | MongoDB (2 máquinas) | MongoDB (4 máquinas) | |
| 10.000.000 de documentos | 26m 44s | 7m 21s | 3m 48s | 1m 23s |
| 20.000.000 de documentos | 15m 58s | 7m 46s | 3m 40s | |
| 80.000.000 de documentos | 53m 11s | 31m 2s | 16m 30s |
Tests de lectura multiusuario (50 usuarios)
En estos dos tests y el siguiente ejecutamos los scripts sobre una base de datos con 30 millones de entradas de log
Mostramos los totales para un dominio escogido al azar
| Mediana | |
| MySQL | 71ms |
| MongoDB | 37ms |
Mostramos todas las entradas en el log para un dominio
| Mediana | |
| MySQL | 321ms |
| MongoDB | 128ms |
| MongoDB (2 máquinas) | 37ms |
Tests de lectura y escritura multiusuario (50 usuarios)
Aquí combinamos lecturas, buscando los datos de un dominio por id, y escrituras, añadiendo una entrada predefinida a la colección que almacena los logs.
80% de lecturas y +20% de escrituras
| Mediana | |
| MySQL | 236ms |
| MongoDB | 75ms |
| MongoDB (2 máquinas) | 37ms |
Conclusiones
Combinando lo obtenido en el y el resultado de los nuevos tets podemos decir:
Rendimiento en lectura
- MongoDB es más rápido en operaciones simples de lectura
- En múltiples lecturas sencillas consecutivas MongoDB es mucho más rápido que MySQL
- En concreto en búsquedas por id de un sólo documento MongoDB ha más que duplicado el rendimiento con respecto a MySQL
- Para búsquedas por una condición (lo que sería una consulta WHERE en SQL) MongoDB ha sido un 250% más rápido que MySQL (buscando todos los registros para un campo de texto con un valor concreto). Con sharding el rendimiento aumenta considerablemente
Funciones de agregación
- Para consultas de agregación MySQL supera a framework nativo de MongoDB. MySQL es mucho más rápido obteniendo datos agregados, de 3 a 6 veces más rápido en los tests que hemos realizado
Rendimiento en escritura
- El rendimiento en escritura de MongoDB ha sido superior en todos nuestros tests
- En escrituras simples consecutivas ha sido entre 2 y 4 veces más rápido
- En lecturas concurrentes MongoDB es más rápido (entre un 15% y un 40% en nuestras pruebas con 50 usuarios)
- Añadir máquinas no produce un aumento del rendimiento en escritura si no se definen reglas de reparto previamente con Tag Aware Sharding
- En caso de definir estas reglas de reparto el rendimiento se multiplica por el número de máquinas usado
Observaciones
- MongoDB es más escalable, lo que significa que cuando la carga de usuarios aumenta el tiempo de respuesta se mantiene estable
- MongoDB es muy flexible. La posibilidad de añadir máquinas (shards) de forma transparente a las aplicaciones nos da una gran flexibildiad a la hora de definir arquitecturas hardware
- El establecimiento de buenas reglas de repartición (y por tanto de conocer cuáles son los patrones de acceso de la aplicación) es fundamental. El papel del DBA y una buena comunicación con los desarrolladores es muy importante
Ver también
El resto de esta serie de artículos



Comentarios
Maravilloso articulo… gracias por la información. pero ahora tengo un dilema, para la aplicación que estoy desarrollando es importante la relación entre los datos, pero también es muy importante la velocidad en escritura y lectura de los datos…. seguiré investigando mas para legar a una conclusión y deicicion final sobre usar mongodb o mysql
Si las relaciones son importantes MySQL (con InnoDB) debería ser suficiente, a menos que las cargas que vayan a soportar los servidores sean masivas.
Si hacer las relaciones desde el lado de la aplicación es algo viable (no estás desarrollando una aplicación que gestione transferencias de dinero, por ejemplo ), siempre puedes desarrollar una clase que gestione la comunicación con la base de datos y las relaciones entre las tablas y así hacer el uso de MongoDB o MySQL transparente a la aplicación.
), siempre puedes desarrollar una clase que gestione la comunicación con la base de datos y las relaciones entre las tablas y así hacer el uso de MongoDB o MySQL transparente a la aplicación.
Echa un vistazo a éste artículo donde presento el proyecto que hice y en el que, entre otras cosas, puedes acceder al código fuente en el que desarrollé varias clases para que los scripts accedan a MySQL o MongoDB. Eso sí, en mi código no gestiono relaciones.
Muchas gracias El articulo me fue de mucha ayuda, creo que las bases dedatos no-relacionales tienen mucho futuro y desarrollo
Añadir comentarios ...